Understanding Backpropagation of Artificial Neural Networks Using an Example with Step-by-step Derivation and Custom Implementations
A neural network model typically learns from iterative training processes to optimize values for its trainable parameters. The major steps in each iteration include forward pass, loss calculation, backward pass and parameter update.
- The forward pass is the process to compute outputs from input.
- Compute loss that is simply a scalar number indicating the disparity betwen the model's predicted output and the ground truth.
- The backward pass is the process to compute gradients of the loss with respect to (w.r.t.) each trainable parameter, which indicates how much the parameters need to change in the negative direction to minimize the loss.
- Update the trainable parameters based on their gradients using a certain algorithm e.g. Adam[1] so that the loss decreases.
Among these steps, the backward pass, which is typically done using backpropagation with chain rule to effectively compute gradients, is the most complex. Fortunately, we are required to define only the forward pass when building a neural network and popular deep learning frameworks such as PyTorch and Tensorflow will do backpropagation for us automatically, referred to as Autograd. While this brings convenience, it also causes confusion around backpropagation, the heart of every neural network. In fact, a clear understanding and hands-on experience with backpropagation is critical for anyone who would like to be an AI expert. Therefore, in this post, I would like to use a simple network example to demonstrate how to compute gradients using the chain rule and manually implement it. Hopefully, this could help those of us with some basic knowledge of neural network and calculus to gain a more solid understanding of it.
This post is organized in the following sections:
- The simple network model
- Derivation of gradients using backpropagation chain rule
- Custom implementations and validation
- Summary
- Extra
- References
1. The simple network model
The example network model is illustrated in Figure 1. It consists of two layers (BatchNorm module and activator Sigmoid) followed by a mean square error (MSE) loss module. Let’s take a look at the forward pass (from bottom to top).
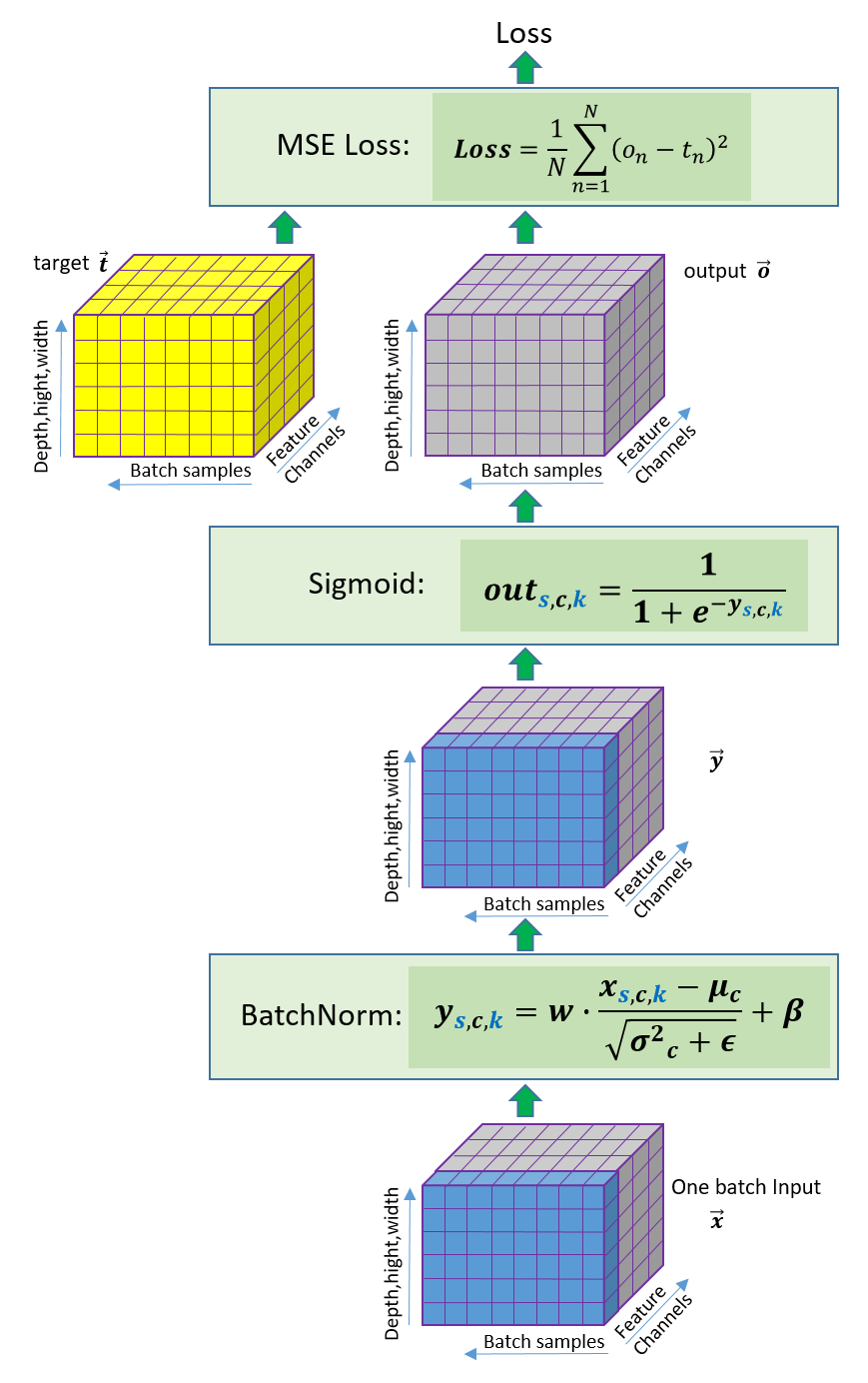
Figure 1 Illustration of the example network.
Input \(\vec x\): a multi-dimensional dataset of \({N_s}\) samples, referred to as a “batch”, and each sample contains \({N_c}\) feature channels of \({N_k} = {N_{height} } \times {N_{row} } \times {N_{col} }\) elements.
where \(s \in \left[ {1,\;{N_s} } \right]\), \(c \in \left[ {1,\;{N_c} } \right]\) and \(k \in \left[ {1,\;{N_k} } \right]\) are the indices along individual dimesions.
BatchNorm layer: a module that was proposed by Ioffe and Szegedy[2] and is widely used in neural networks to help make the training faster and more stable through normalization of the batch data by re-centering and re-scaling. BatchNorm is applied across all samples in the batch but for each feature channel separately. The blue color of the data in Figure 1 represents one channel. The output \(\vec y\) from BatchNorm is computed as
where \({w_c}\) and \({\beta _c}\) are the trainable parameter, \({\mu _c}\) and \(\sigma _c^2\) are the mean and biased variance of the \(c\)-th channel of the given batch data,
\({\mu _c} = \frac{1}{ { {N_s} \times {N_k} } }\mathop \sum \limits_{s = 1}^{ {N_s} } \mathop \sum \limits_{k = 1}^{ {N_k} } {x_{s,c,k} }\) (3)
\(\sigma _c^2 = \frac{1}{ { {N_s} \times {N_k} } }\mathop \sum \limits_{s = 1}^{ {N_s} } \mathop \sum \limits_{k = 1}^{ {N_k} } {\left( { {x_{s,c,k} } - {\mu _c} } \right)^2}\) (4)
Please note that because all computation are cross the dimensions of \(s\) and \(k\), we can combine these dimensions into a single index \(i \in \left[ {1,{N_s} \times {N_k} } \right]\) and rewrite Equations (2) through (4) equivalently as the following for simplicity:
\({y_{c,i} } = {w_c} \cdot \frac{ { {x_{c,i} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } } + {\beta _c}\) (5)
\({\mu _c} = \frac{1}{ { {N_i} } }\mathop \sum \limits_{j = 1}^{ {N_i} } {x_{c,j} }\) (6)
\(\sigma _c^2 = \frac{1}{ { {N_i} } }\mathop \sum \limits_{j = 1}^{ {N_i} } {\left( { {x_{c,j} } - {\mu _c} } \right)^2}\) (7)
where \({N_i} = {N_s} \times {N_k}\) and \(j \in \left[ {1,{N_i} } \right]\).
We also want to mention that BatchNorm is selected to be included in this example because while its forward computing is much simpler than some other modules such as ConvNd and ConvTransNd, its backward computing for gradients is surprisingly more complex than those modules. By going through the harder example of BatchNorm, we hope it helps with the other easier cases.
Sigmoid layer: an activator function whose output \(\vec z\) is defined as
\(\vec z\) is also the output of the network. Sigmoid is applied to each element in each channel of each sample independently. The index of \(c\) is kept in Equation (8) for convenience of gradient derivation using backpropagation later. So far the equations (5) and (8) form the forward pass of the network.
MSE Loss function: the scalar MSE loss, \(L\), is computed as
where \(N = {N_c} \times {N_i}\). In other words, the loss is the mean of the squared error of all elements in all channels of all samples between the network output \(\vec z\) and the target dataset \(\vec t\).
With all components of this example network being defined, the main goal here is to compute the gradients of the loss \(L\) w.r.t. the trainable parameters \(\vec w\) and \(\vec \beta \) and the input \(\vec x\) : \(\frac{ {\partial L} }{ {\partial \vec w} }\), \(\frac{ {\partial L} }{ {\partial \vec \beta } }\), and \(\frac{ {\partial L} }{ {\partial \vec x} }\), respectively. You might have a question: since \(\vec x\) is an input instead of a trainable parameter, why bother to compute the partial derivative \(\frac{ {\partial L} }{ {\partial \vec x} }\)? The answer is that BatchNorm in a network typically takes the output from other layers (e.g. Conv2d, which is not included in this network for simplicity) as its input \(\vec x\), and calculation of gradients in those layers requires \(\frac{ {\partial L} }{ {\partial \vec x} }\) being available.
BTW, this post is not focused on parameter update from the gradients, so that part is not included in this post. We can write separate posts about that too.
2. Derivation of the gradients
2.1 The chain rule
We will follow the chain rule to do backpropagation to compute gradients. Since there is a huge amount of online resources available talking about the chain rule, we just summarize its main idea here. Given a function \(L\left( { {x_1},{x_2}, \ldots {x_N} } \right)\) as
Then the gradient of \(L\) w.r.t \({x_i}\) can be computed as
Equation (11) can be understood from two perspectives:
- Summation means that all possible paths through which \({x_i}\) contributes to \(L\) should be included
- Product means that, along each path \(m\), the output gradient equals the upstream passed in, \(\frac{ {\partial L} }{ {\partial {f_m} } }\), times the local gradient, \(\frac{ {\partial {f_m} } }{ {\partial {x_i} } }\).
2.2 Dimensions of the gradients
Please note that, the loss function in a neural network gives a scalar value output loss. The gradient of the loss w.r.t. any trainable parameter or input variable should have the same dimension as that parameter or variable, whether it is another scalar, or a 1-D vector, or N-D array.
For example, the trainable parameter \(\vec w = \left( { {w_1},{w_2}, \ldots {w_{ {N_c} } } } \right)\) of the Batch Norm module is a 1-D vector containing \({N_c}\) elements with one element corresponding to one channel; therefore, the gradient \(\frac{ {\partial L} }{ {\partial \vec w} }\) should also be a 1-D vector containing \({N_c}\) elements, \(\frac{ {\partial L} }{ {\partial \vec w} } = \left( {\frac{ {\partial L} }{ {\partial {w_1} } },\frac{ {\partial L} }{ {\partial {w_2} } }, \ldots \frac{ {\partial L} }{ {\partial {w_{ {N_c} } } } } } \right)\).
2.3 Derivation of the gradient \(\frac{ {\partial L} }{ {\partial \vec w} }\)
Let’s first derive the upstream gradients using the chain rule to derive \(\frac{ {\partial L} }{ {\partial \vec w} }\) or element-wise \(\frac{ {\partial L} }{ {\partial {w_c} } }\).
From Equation (9) for the MSE loss function, we have the partial derivative
From Equation (8), we have the local partial derivative of the sigmoid function
Note that, there is only one path from \({y_{c,i} }\) to \(L\), which is via \({z_{c,i} }\). Therefore, the gradient of \(L\) w.r.t. \({y_{c,i} }\) is simply the product of \(\frac{ {\partial L} }{ {\partial {z_{c,i} } } }\) and \(\frac{ {\partial {z_{c,i} } } }{ {\partial {y_{c,i} } } }\) without summation.
This is also the upstream gradient for the BatchNorm layer. The local gradient for \(\vec w\) can be derived from Equation (5)
Now, using the chain rule, we take the product of the upstream gradient from Equation (14) and the local gradient from Equation (15), and sum all paths together to get
The upstream gradient terms in Equations (14) and (16) are not substituted with their expanded format because their values have been computed and are available from upstream calculation, so there is no need to re-compute them every time they are used. That’s why the chain rule is an effective method for backpropagation.
2.4 Derivation of gradient \(\frac{ {\partial L} }{ {\partial \vec \beta } }\)
Similarly, the local gradient for \(\vec \beta \) can be derived from Equation (5) for BatchNorm
Now using the chain rule, we have
2.5 Derivation of gradient \(\frac{ {\partial L} }{ {\partial \vec x} }\)
Derivation of gradient w.r.t \(\vec x\) is more complicated than \(\vec w\) and \(\vec \beta \) because each \({x_{c,i} }\) directly contributes to \({y_{c,i} }\) and also indirectly contributes to other \({y_{c,k} }\) elements via \({\mu _c}\left( { {x_{c,1} }, \ldots ,{x_{c,{N_i} } } } \right)\) and \({\sigma ^2}_c\left( { {x_{c,1} }, \ldots ,{x_{c,{N_i} } } } \right)\), as shown in Figure 2. To help understand the underneath logic, we will demonstrate two different ways to solve this challenge and achieve the same solution.
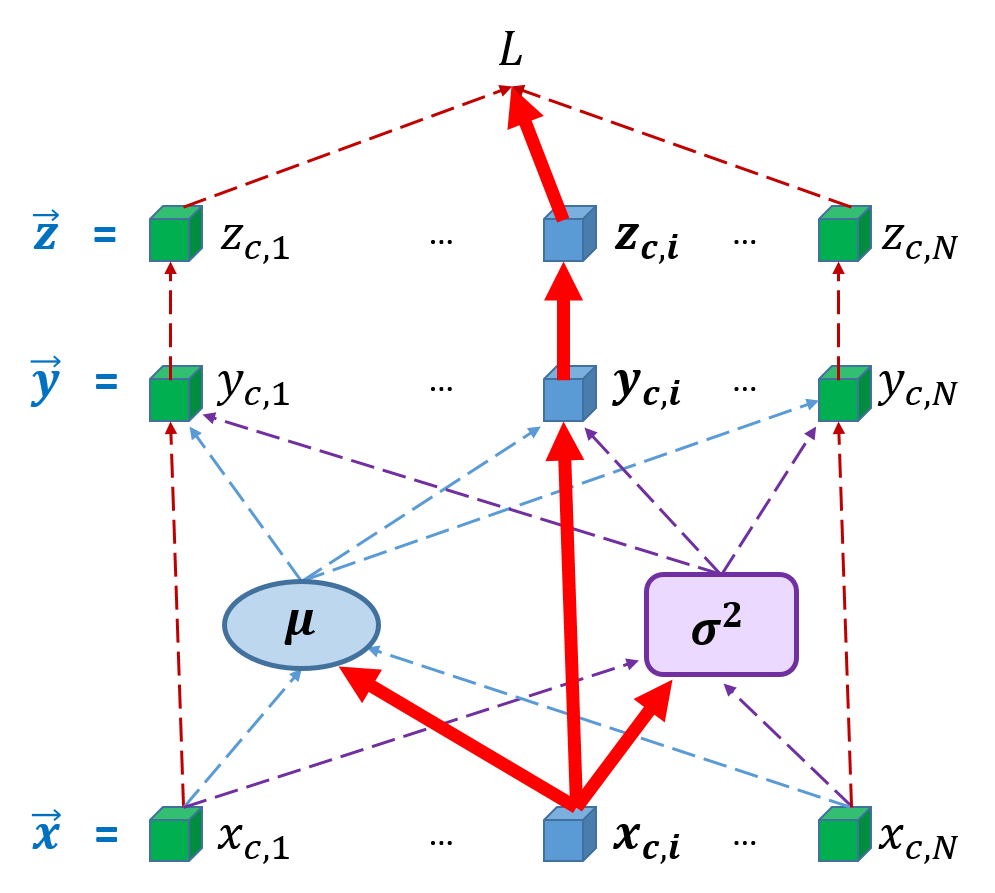
2.5.1 Solution 1 for derivation of gradient \(\frac{ {\partial L} }{ {\partial \vec x} }\)
Using the chain rule, we have
Based on Equation (5), for \(k = i\), we have
\(\frac{ {\partial {y_{c,i} } } }{ {\partial {x_{c,i} } } } = {w_c}\frac{ {\sqrt {\sigma _c^2} \cdot \frac{\partial }{ {\partial {x_{c,i} } } }\left( { {x_{c,i} } - {\mu _c} } \right) - \left( { {x_{c,i} } - {\mu _c} } \right)\frac{\partial }{ {\partial {x_{c,i} } } }\sqrt {\sigma _c^2} } }{ {\sigma _c^2} }\)
\( = {w_c}\frac{ {\frac{ { {N_i} - 1} }{ { {N_i} } }\sqrt {\sigma _c^2} - \left( { {x_{c,i} } - {\mu _c} } \right) \cdot\frac{1}{2} \cdot \frac{1}{ {\sqrt {\sigma _c^2} } } \cdot \frac{ {2\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i} } } } }{ {\sigma _c^2} }\)
\( = {w_c}\frac{ {\left( { {N_i} - 1} \right)\sigma _c^2 - { {\left( { {x_{c,i} } - {\mu _c} } \right)}^2} } }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\) (20)For \(k \ne i\), we have
\(\frac{ {\partial {y_{c,k} } } }{ {\partial {x_{c,i} } } } = {w_c}\frac{ {\sqrt {\sigma _c^2} \frac{\partial }{ {\partial {x_{c,i} } } }\left( { {x_{c,k} } - {\mu _c} } \right) - \left( { {x_{c,k} } - {\mu _c} } \right)\frac{\partial }{ {\partial {x_{c,i} } } }\sqrt {\sigma _c^2} } }{ {\sigma _c^2} }\)
\( = {w_c}\frac{ {\sqrt {\sigma _c^2} \left( { - \frac{1}{ { {N_i} } } } \right) - \left( { {x_{c,i} } - {\mu _c} } \right) \cdot \frac{1}{2} \cdot \frac{1}{ {\sqrt {\sigma _c^2} } } \cdot \frac{ {2\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i} } } } }{ {\sigma _c^2} }\)
\( = - {w_c}\frac{ {\sigma _c^2 + \left( { {x_{c,i} } - {\mu _c} } \right)\left( { {x_{c,k} } - {\mu _c} } \right)} }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\) (21)Substitute Equations(20) and (21) into (19), we have
\(\frac{ {\partial L} }{ {\partial {x_{c,i} } } } = \frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } }{w_c}\frac{ {\left( { {N_i} - 1} \right)\sigma _c^2 - { {\left( { {x_{c,i} } - {\mu _c} } \right)}^2} } }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } } - \mathop \sum \limits_{k \ne i} \frac{ {\partial L} }{ {\partial {y_{c,k} } } }{w_c}\frac{ {\sigma _c^2 + \left( { {x_{c,i} } - {\mu _c} } \right)\left( { {x_{c,k} } - {\mu _c} } \right)} }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\)
\( = \left( {1 - \frac{1}{ { {N_i} } } } \right)\frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { { {\left( { {x_{c,i} } - {\mu _c} } \right)}^2} } }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k \ne i} \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \frac{ { {w_c}\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\mathop \sum \limits_{k \ne i} \left( { {x_{c,k} } - {\mu _c} } \right)\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\)
\( = \frac{ { {w_c} } }{ {\sqrt { {\sigma ^2}_c} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c}{ {\left( { {x_{c,i} } - {\mu _c} } \right)}^2} } }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k \ne {\rm{i} } } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \frac{ { {w_c}\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3} } }\mathop \sum \limits_{k \ne {\rm{i} } } \left( { {x_{c,k} } - {\mu _c} } \right)\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \frac{ { {w_c}\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i}{ {\sqrt {\sigma _c^2} }^3}{w_c} } }\mathop \sum \limits_{k = 1}^{ {N_i} } {w_c}\left( { {x_{c,k} } - {\mu _c} } \right)\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,{\rm{i} } } } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \frac{ { {y_{c,i} } - {\beta _c} } }{ { {N_i}\sqrt {\sigma _c^2} {w_c} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \left( { {y_{c,k} } - {\beta _c} } \right)\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\) (22)2.5.2 Solution 2 for derivation of gradient \(\frac{ {\partial L} }{ {\partial \vec x} }\)
Solution 2 is very similar to another very nice post by Kevin Zakka[3]. From Figure 2 above, we see that, given \({x_{c,i} }\), it has only 3 direct contribution paths to \({y_{c,i} }\), \({\mu _c}\) and \({\sigma ^2}_c\), as highlighted using bold red arrow. Therefore using the chain rule from this perspective, we have the second solution:
The 1st item \(\frac{ {\partial L} }{ {\partial {y_{c,i} } } }\) is the upstream gradient and available from Equation (14). Let’s derive the rest components one by one.
The 2nd item \(\frac{ {\partial {y_{c,i} } } }{ {\partial {x_{c,i} } } }\) can be derived from Equation (5)
Now, let’s derive the 3rd item \(\frac{ {\partial L} }{ {\partial {\mu _c} } }\). Note that, \({\mu _c}\) has direct contribution paths to both \(\vec y\) and \(\sigma _c^2\), so we have
\(\frac{ {\partial L} }{ {\partial {\mu _c} } } = {\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\frac{ {\partial {y_{c,k} } } }{ {\partial {\mu _c} } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\frac{ {\partial \sigma _c^2} }{ {\partial {\mu _c} } }\)
\( = {\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\frac{ {\partial {y_{c,k} } } }{ {\partial {\mu _c} } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\frac{\partial }{ {\partial {\mu _c} } }\left( {\frac{1}{N}\mathop \sum \limits_{k = 1}^{ {N_i} } { {\left( { {x_k} - {\mu _c} } \right)}^2} } \right)\)
\( = { - \mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\cdot\frac{1}{ { {N_i} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{\partial }{ {\partial {\mu _c} } }{\left( { {x_k} - {\mu _c} } \right)^2}\)
\( = { - \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\cdot\frac{1}{ { {N_i} } }\mathop \sum \limits_{k = 1}^{ {N_i} } 2\left( { {\mu _c} - {x_k} } \right)\)
\( = { - \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\cdot2\left( {\frac{1}{ { {N_i} } }\mathop \sum \limits_{k = 1}^{ {N_i} } {\mu _c} - \frac{1}{ { {N_i} } }\mathop \sum \limits_{k = 1}^{ {N_i} } {x_k} } \right)\)
\( = { - \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\cdot2\left( { {\mu _c} - {\mu _c} } \right)\)
\( = { - \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } } + 0\) (25)BTW, from the above derivation, we learned that \(\frac{ {\partial \sigma _c^2} }{ {\partial {\mu _c} } } = 0\).
Let’s move on to the 4th item \(\frac{ {\partial {\mu _c} } }{ {\partial {x_{c,i} } } }\). Because \({\mu _c} = \frac{1}{ { {N_i} } }\mathop \sum \limits_{i = 1}^{ {N_i} } {x_{c,i} }\), it’s easy to have
Next, for the 5th item \(\frac{ {\partial L} }{ {\partial \sigma _c^2} }\).
\(\frac{ {\partial L} }{ {\partial \sigma _c^2} } = \mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\frac{ {\partial {y_{c,k} } } }{ {\partial \sigma _c^2} }\)
\( = \mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\frac{\partial }{ {\partial \sigma _c^2} }\left( { {w_c}\frac{ { {x_{c,k} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } } + {\beta _c} } \right)\)
\( = \mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\left( { {x_{c,k} } - {\mu _c} } \right)\frac{\partial }{ {\partial \sigma _c^2} }\left( {\frac{1}{ {\sqrt {\sigma _c^2} } } } \right)\)
\( = \mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\left( { {x_{c,k} } - {\mu _c} } \right)\left( { - \frac{1}{2}\cdot\frac{1}{ { { {\left( {\sqrt {\sigma _c^2} } \right)}^3} } } } \right)\)
\( = - \frac{1}{2}\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\frac{ { {x_{c,k} } - {\mu _c} } }{ { { {\left( {\sqrt {\sigma _c^2} } \right)}^3} } }\) (27)For the 6th and also last item \(\frac{ {\partial \sigma _c^2} }{ {\partial {x_{c,i} } } }\), we have
Derivation of Equation (28) used the intermediate result of \(\frac{ {\partial \sigma _c^2} }{ {\partial {\mu _c} } } = 0\) from Equation (25).
Now, substituting these derivations back into Equation (23), we have
\(\frac{ {\partial L} }{ {\partial {x_{c,i} } } } = \frac{ {\partial L} }{ {\partial {y_{c,i} } } }\frac{ {\partial {y_{c,i} } } }{ {\partial {x_{c,i} } } } + \frac{ {\partial L} }{ {\partial {\mu _c} } }\frac{ {\partial {\mu _c} } }{ {\partial {x_{c,i} } } } + \frac{ {\partial L} }{ {\partial \sigma _c^2} }\frac{ {\partial \sigma _c^2} }{ {\partial {x_{c,i} } } }\)
\( = \frac{ {\partial L} }{ {\partial {y_{c,i} } } }\frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } } + \left( { - \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } } \right)\frac{1}{ { {N_i} } } + \left( { - \frac{1}{2}\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\frac{ { {x_{c,k} } - {\mu _c} } }{ { { {\left( {\sqrt {\sigma _c^2} } \right)}^3} } } } \right)\cdot\frac{ {2\left( { {x_{c,i} } - {\mu _c} } \right)} }{ { {N_i} } }\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,i} } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \left( {\frac{1}{ { {N_i}\sqrt {\sigma _c^2} } }\frac{ { {x_{c,i} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \left( {\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\frac{ { {x_{c,k} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } } } \right)} \right)\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,i} } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \left( {\frac{1}{ { {N_i}\sqrt {\sigma _c^2} } }\cdot\frac{ { {w_c} } }{ { {w_c} } }\cdot\frac{ { {x_{c,i} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \left( {\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot{w_c}\frac{ { {x_{c,k} } - {\mu _c} } }{ {\sqrt {\sigma _c^2} } } } \right)} \right)\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,i} } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \left( {\frac{ { {y_{c,i} } - {\beta _c} } }{ { {N_i}{w_c}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \left( {\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\cdot\left( { {y_{c,k} } - {\beta _c} } \right)} \right)} \right)\)
\( = \frac{ { {w_c} } }{ {\sqrt {\sigma _c^2} } }\frac{ {\partial L} }{ {\partial {y_{c,i} } } } - \frac{ { {w_c} } }{ { {N_i}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \frac{ {\partial L} }{ {\partial {y_{c,k} } } } - \frac{ { {y_{c,i} } - {\beta _c} } }{ { {N_i}{w_c}\sqrt {\sigma _c^2} } }\mathop \sum \limits_{k = 1}^{ {N_i} } \left( { {y_{c,k} } - {\beta _c} } \right)\frac{ {\partial L} }{ {\partial {y_{c,k} } } }\) (29)Equation (29) is identical to Equation (22): two solutions, the same answer. We took this effort to demonstrate that a problem can be solved using different solutions. Derivation is done!
3. Custom implementations and validation
Two separate implementations of the forward pass, loss calculation, and backpropagation are demonstrated in this post. The 1st one uses PyTorch and the 2nd one uses Numpy. The functions and corresponding equations are summarized in Table below.
| Functions | Equations |
|---|---|
| BatchNorm Forward | (5) |
| Sigmoid Forward | (8) |
| MSE Loss | (9) |
| MSE Gradient | (12) |
| Sigmoid Gradient | (14) |
| BatchNorm Gradients | (16), (18), (22) |
While the Numpy version is quite self-explanatory, it is worth mentioning that the PyTorch version of our custom autograd functions of BatchNorm, Sigmoid and MSELoss are implemented by subclassing torch.autograd.Function, respectively. The forward() and backward() functions are overridden based on the equations above and will be executed when the forward pass and backpropagation are triggered. Please also note that the input list of upstream gradients of the backward() function must match the output list of the forward() function, and the output gradient list of the backward() function must match the input list of the forward() function. In addition, the input, output and intermediate data of the forward() function can be cached using the save_for_backward() function so that they can be used in the backward() function without re-calculation.
A small constant number \(\epsilon = 1E-5\) is added to \(\sigma _c^2\) in order to avoid divide-by-zero exception just in case, just as done by the PyTorch built-in BatchNorm.
To serve as a reference for comparison, the same network was also implemented using PyTorch’s built-in modules of BatchNorm[4], Sigmoid and MSELoss. The network output, loss, gradients of the loss w.r.t. \(\vec w\), \(\vec \beta \) and \(\vec x\) from the custom implementations were compared to the reference and the results matched.
You can find the source code on GitHub. If you like, you can also implement using Tensorflow as well to gain hands-on experience.
4. Summary
In this post, we used a simple BatchNorm-Sigmoid-MSELoss network to demonstrate how to use the chain rule to derive gradients in backpropagation and how to implement the custom autograd functions. We hope that, by going over this example, it can help obtain a deeper understanding of the fundamentals of neural networks, especially about backpropagation.
5. Extra
In the derivation above we found that the partial derivatives of the biased variance \({\sigma ^2}\) w.r.t to the input \(\vec x\) and mean \(\mu \) are \(\frac{ {\partial {\sigma ^2} } }{ {\partial {x_i} } } = \frac{ {2\left( { {x_i} - \mu } \right)} }{N}\) and \(\frac{ {\partial {\sigma ^2} } }{ {\partial \mu } } = 0\), respectively. If it sounds a little bit surprising to see these results and especially \(\frac{ {\partial {\sigma ^2} } }{ {\partial \mu } } = 0\), you can write a few lines of Python codes to verify it, just as below.
import torch
x = torch.rand(10, requires_grad=True, dtype=torch.float64)
m = x.mean()
m.retain_grad()
v = ((x-m)**2).sum()/x.numel()
v.backward()
manual_grad_dvdx = (x-m)*2/x.numel()
print('dv/dm = ', m.grad)
print('torch dv/dx= ', x.grad.detach().numpy())
print('manual dv/dx= ', manual_grad_dvdx.detach().numpy())
6. References
- [1] Diederik P. Kingma and Jimmy Lei Ba (2014). Adam : A method for stochastic optimization.
- [2] Sergey Ioffe and Christian Szegedy (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
- [3] Kevin Zakka (2016). Deriving the Gradient for the Backward Pass of Batch Normalization.
- [4] PyTorch documentation. BatchNorm3d.